
Create your own virtual persona on Databricks
- Aarni

- Mar 1
- 4 min read
Updated: Mar 2
What if an agent could think and act exactly like you?
I'm probably not the only one who's thought about this more than once. Wouldn't it be great to clone yourself? Your clone could then handle all the work while you can take it easy. Yes we are still waiting on that cloning machine, but there's something else on the table: Turning your digital meta and behavioral data into an actual digital version of you.
Every Databricks user leaves a trail of activity in system tables - queries, jobs, services, costs, login patterns and more. And that data sits unused too often. What if you could convert it into your own Digital Twin: an AI agent you can talk to that knows your work habits, expertise and personality?
Meet your Virtual Persona
Click "View on Github" to access open source repo.
Turn your Databricks footprint into a virtual version of you
This Repo solution demonstrates how it's possible to create virtual personas based on system log data. By analysing your Databricks workspace activity. The app builds a rich behavioural profile and converts it into your own Digital Twin: an AI you can talk to that knows your work habits, expertise and personality. Quite cool.
Built as a Databricks App using Flask. Runs entirely inside your workspace using on-behalf-of-user (OBO) authentication (accessing own log data only) - your data stays yours. Both local and Databricks deployed supports are included (remember to populate configs).
The App has 5 pages:
Home page
Check Access - validate your access to required system tables
Run Analysis - takes 5-15 min, depending on how much log data you have
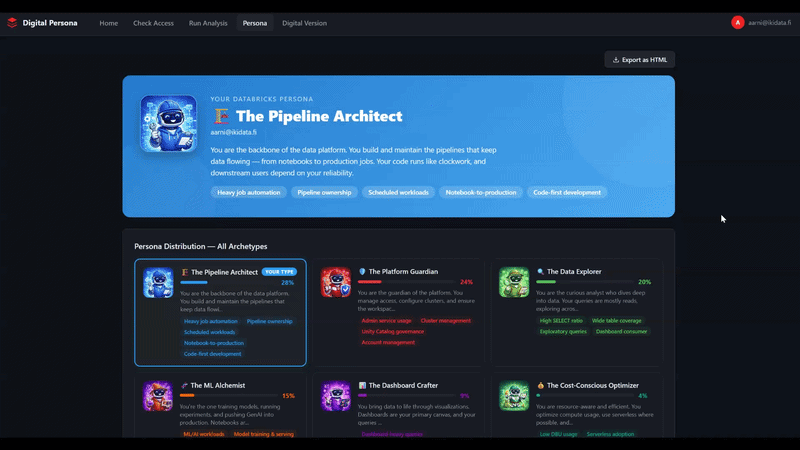
Persona - really detailed and rich summary of your Databricks usage - showing only a little here since I don't want to reveal too much of my own summary
Digital Version - your digital version system prompt is auto-generated and you can talk with it / copy the system prompt to other agent use-cases
The 6 Archetypes:
Your behaviour is scored against 6 data-driven archetypes
Archetype | You probably... |
🏗️ Pipeline Architect | Build scheduled jobs and automate data flows |
🔍 Data Explorer | Run lots of exploratory SELECT queries |
🛡️ Platform Guardian | Manage clusters, permissions, and governance |
📊 Dashboard Crafter | Create and publish BI dashboards |
🧪 ML Alchemist | Use MLflow, model serving, or GenAI tools |
💰 Cost-Conscious Optimizer | Keep compute lean and efficient |
Achievement Badges
20+ badges earned automatically from your data:
🏆 SQL Centurion — 100+ queries executed
🦉 Night Owl — peak activity after 20:00
✅ Zero Downtime — 100% pipeline success rate
🔥 Iron Streak — 30+ consecutive active days
🤖 AI Pioneer — active GenAI endpoint usage
📈 Top 10% Active — more active than 90% of workspace peers
...and 15+ more
See virtual persona creation on Databricks in action
...Based on what you've shared, I'm a data engineer and platform builder who works best late at night, alone and focused. Build things designed to run without supervision - pipelines, clusters, agents - is genuinely deep into the agent/AI layer right now, not as a trend but as a serious architectural shift...
Not bad, not bad. It was actually really on point about me. I naturally didn’t want to expose all the information here in the GIF.
Keep in mind that this isn't a real agent, but just a showcase to demonstrate what's possible. It essentially generates a system prompt based on your Databricks metadata, which you can chat with directly or plug into your own agent use cases. A real implementation would go much deeper: richer analysis, proper memory handling, actual agent capabilities etc. But even this simple version produces surprisingly accurate results. You get the idea of what these big AI companies are doing 😉
World is changing, quicker than expected
This virtual persona analyzer runs entirely on Databricks metadata with one simple goal in mind: demonstrate how easy it has become to start automating these kinds of processes.
By crunching and analyzing large volumes of log data behavioral patterns combined with master data, you can construct what I call a virtual DNA. From there, it's just a matter of converting that information into an optimized agent that can handle tasks on your behalf.
The pace of change is brutal. What used to take months can, in the best case, be done in hours. It means the old way of working isn't just inefficient, it's dying. Basic data and platform engineering tasks can and will be automated. Agentic virtual personas can act as your own team, instead of waiting a week for a meeting that ends without any real decisions. Technology changes how we work - that's certain. The question is whether organizations will evolve alongside it, or stay anchored to the old world and slowly become irrelevant. Adapt or deprecate.
It seems code itself is slowly becoming "worthless". Seriously. Almost anything can be reverse-engineered, which is exactly why open source is going to win, one way or another. So what actually holds value? Understanding the problem deeply - how it's framed, approached and solved. That is worth far more than the code itself.

Written by Aarni Sillanpää
Evolve with technology or devolve without it



Comments