
This is the story how I have automated Databricks with self-improving ACE multi-agents
- Aarni

- Dec 6, 2025
- 10 min read
Updated: Mar 2
There's a new admin in the town - KRATTI
Everything began in 2020...
It was an innocent time before ChatGPT, Databricks Unity Catalog, system tables and COVID was running wild... Wait a second! Anyway, it was the moment I became truly enlightened to the fact that traditional data operations can and will be automated. It was just a matter of time. Instead of building one-off solutions and integrations, Databricks was already harmonizing and standardizing best practices. And you know what happens after everything is harmonized? it’s time to start the automation marathon. Even back then, the guiding motto was "full automation, zero maintenance".

The dream was there, but it would have required too many complex rule-based decision trees and endless if/else conditions. Nobody has time for that kind of work.
Let’s fast-forward a couple of years to the moment when LLMs with tool support were introduced. The fun begins here. This truly opened the doors to start automating things smartly. I think people have mainly understood agents wrong, since it’s not about creating low-code/no-code, aka low-value "agents". It’s all about taking the best knowledge and empowering your specialized custom agents with it. You cannot clone humans or consciousness (yet), but you can teach your agents how to use that knowledge. And let me tell you, it’s already incredibly efficient.
So here's my story how I’ve automated my Databricks setup with self-improving ACE multi-agents, all on a Coca-Cola and pizza budget during the weekends. And if you’re not familiar with ACE, it means Agentic Context Engineering. I don’t want agents to rewrite their own code or retrain parameters, but to keep their "behavior" the same and simply optimize context data dynamically.
Individual agents assemble the puzzle
The whole idea of multi-agents is to create highly specialized agents with limited scope. It's the cheat code to achieve production-ready solutions, at least in my experience. Here it meant that I created narrow and clearly defined scopes for my specialized agents. I wanted to test the concept, so I decided to use the following domains at first:
Cost optimization
Workflow optimization
Data management optimization
DLT Pipeline creator (yes it's DLT for me, I don't like the new name :D)
And couple of others
*Planning to scale agent count up to ~15 in the near future
It meant that I took my hard-earned practical experience and gave that knowledge to a dedicated agents and then built the necessary tools based on it. It was important to find a balance between the required autonomy and the parameterized tools. Since Databricks has been standardizing everything so well, I could use the prebuilt tools effectively and truly rely on them to always work as intended (plz no breaking changes). If this had been a software provider using random logic, it wouldn’t have worked (I'm not pointing to Germany). The architecture here was to have clearly isolated domains where I could focus on each agent on its own, optimizing performance on limited tasks and ensuring proper automation. As a reminder, I'm not creating chatbots but automation agents. I guess it’s a lot easier since I don’t have to worry about unpredictable user prompts and can rely on consistency.
To talk about a couple of agents here, let's start with cost optimization agent. This was the first one and I have been working on this for ages. It contains basic KPI monitoring, automated cost outlier detection with root causes, an auto-fixing possibility, etc. Databricks has a lot of hidden costs and this has saved me a significant amount of money. Since I am testing a lot of new features and possibilities all the time, I’d say I have saved roughly ~35% of my costs thanks to this. Haven’t needed to worry about costs at all for a long time and wasn’t even able to burn all my free Azure credits in time.
Workflow optimization monitors my jobs and will auto-fix them whenever it’s possible (the agent’s choice). If not, it will create a DevOps ticket (which I don’t read) and inform me via Slack that manual fixing is needed with code recommendations. This is a bit of an old approach (solution is +1.5 years old) and nowadays it could be quickly reconfigured to fix all broken workflows and integrate into CI/CD pipelines. It’s quite a trivial problem to automate, but I haven’t had time to do that upgrade yet. And forgot to mention, knows all about my jobs as well.
Then another quite interesting agent would be the DLT pipeline creator. This is also an old approach (+1 year) from when I created this. In short, automating basic pipeline creation for agents is easy, in theory. The problem isn't coding but logic what needs to be implemented - automatically providing the agent relevant context data to do necessary data transformation. If you have standardized ETL process with a good documentation, it's not problem at all. But usually that's not the case and vital information is scattered all around company and SMEs, making accessing necessary knowledge more difficult than expected. But let's move on to even more interesting parts.
Taking agent architecture to the next level
After validating that the specialized agent approach was working, it was time to take things to the next level and build a dynamically working multi-agent entity. Here you can see how everything works on an abstract level. The agents have been modularized as their own entities and my main agent has its own "daily tasks", simulating a virtual employee. On top of that, I can update tasks or have a direct connection via Slack, for example from my phone. I also included dynamic session memory optimizers to keep token usage as efficient as possible for each agent, not to forget LLM-as-a-judges. Since this is quite a new thing, I have faced many interesting challenges that required unique problem-solving.
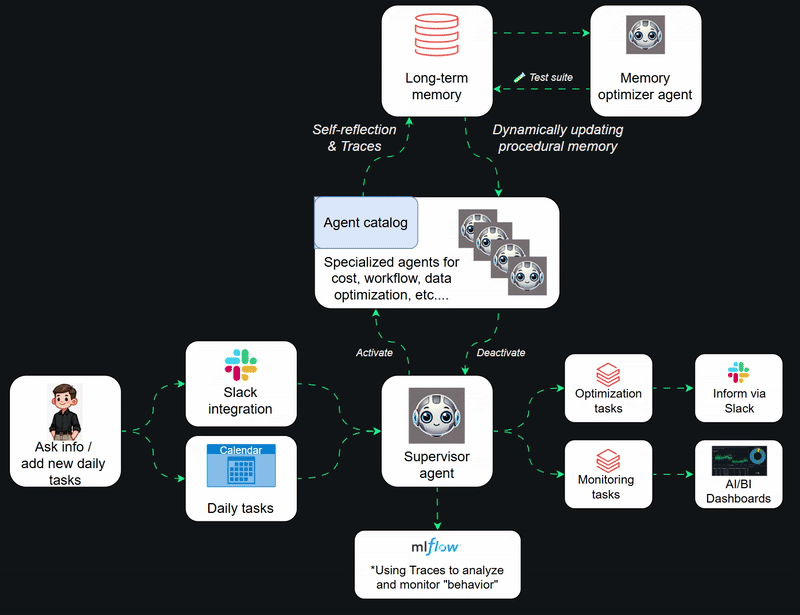
Scalability was the first problem to solve
After building the first specialized agents, it was time to start compiling everything together. To optimize token usage and performance, I decided to use a supervisor approach. Handling full memory between agents didn’t provide any extra value, on the contrary. The specialized agents needed to focus on their domain and be able to be reused for many use cases. And here was the first problem I faced, scalability.
I have seen many multi-agent solutions already and almost all of them had the same issue: dynamic scalability in agent selection. You have to preselect which tools/agents your supervisor agent can use. To me, this is a lazy approach. I wanted to have a working, composable agent catalog. The requirements were that you can easily see which agents are usable (with descriptions), can easily and dynamically update agents there and activate and deactivate agents during the supervisor agent’s run. Runs can be quite long, so you cannot keep everything activated all the time and burn extra tokens constantly. And no, I’m not talking about MCP here.
Agents should see which agents are available, activate the relevant ones, use them and then deactivate them. All of that easily and dynamically. Since I always pick the easiest option, of course had to built my own solution. An agent catalog that stores all my specialized agents, from which the supervisor (or other agents) can select the most suitable one: activate it, use it and then deactivate it. Unity Catalog is really handy nowadays, but remember that you need to have automated and robust processes built on top of it.

Absurd cost-effectiveness
In Databricks it’s possible to deploy agents via model serving, but it comes with a cost. And if I were to use my own custom MCP server via Databricks Apps, it would add extra static costs per day. Not to mention requiring each agent to be deployed or included in the Apps code with limited capabilities. Luckily zero scaling with agent deployment works now really nicely, which helps a lot with cost optimization. Another thing to consider was MLflow tracing data processing. Deployed agents in Databricks use serverless, which means MLflow traces files need to be updated to your own workspace. The current option (while writing this) seems to be using a serverless DLT pipeline to do the job (delta sync). The problem with that feature is that it's not bundling agents but having own pipeline for each deployed agent. By default it was scheduled to run every 15 minutes, so it would incur extra costs if not reconfigured ASAP. So I'd recommend to use own code & workflow to convert MLflow tracing to delta table. Another thing was that since the deployed agents use serverless, I'd need to enable Lakebase or use a SQL warehouse connector to store all memory, which would add additional costs. So yes, there were quite many cost components to consider. Luckily the only enterprise architecture meeting I had to go through was with myself and I wasn’t burdened with extra requirements.
Example default cost structure at a daily level for 1+7 agents:
Agent deployment: - ~0$-15$ * 8 (0.07$ * 10.48 DBU/hour - scale to zero is really handy nowadays)
MCP serving hosting: ~ 11usd (0.95$ * 0.5 DBU/hour)
Lakebase: ~ 9.5usd (0.4$ * 1 DBU/hour)
MLflow tracing: Xusd
Okay, this was a bit absurd cost that I will exclude it from now on. It's now been fixed from previous version and moved under delta sync feature instead of automatically activated workflows.
To summarize, 1+7 specialized agents deployed, own custom MCP server using Apps and Lakebase for memory (excluding MLflow tracing), the total daily costs would be:
8 * 7.5$ + 11$ + 9.5$ = ~ 80.5$ (50% up time with zero-scaling)
There is a lot of variation depending on the approach, but the costs would easily exceed $75 per day if not optimized and the easiest approach would be chosen. That's over $2,000 per month, which was too expensive for my pizza budget - especially now that I haven’t eaten pizza for a while. So I designed my own solution, ensuring I had same capabilities while reducing costs to approximately 2$ per day. Yep, you read that right. And no, I’m not spilling my secrets here :) But keep in mind that this is not for enterprise but my own needs. Otherwise this set-up would be really nice and as long as generated ROI exceed costs (which should), it's more than justified. Generated value > costs, keep that in mind always.
Disclaimer: This was based on the current options available on Azure EU and might contain outdated information. The point is that you can use Databricks very cheaply, but if used incorrectly, it can become expensive quickly. The technology works really well, but it requires knowledge to use it smartly. Otherwise scaling usage may lead to unexpected costs. That’s why I originally created my own Cost Guarding Agent KRATTI.
From prompt optimization to creating self-improving agents
The challenge was building agents that continuously improve. The world is messy and constantly changing, so instead of chasing system prompt optimization hype (which often targets static benchmarks and relies on perfect training data), I focused on adaptability and expecting the unexpected. It was time to choose a new approach here. I’ve been developing a self-improving agent approach for some time and when ACE (Agentic Context Engineering) was published, I found it very similar and appealing. Given that commercial LLMs are already powerful enough, the key is providing the right "compute power" and supplying the necessary context. That is a more agile and cost-effective strategy than repeatedly fine-tuning smaller models (which aren’t quite there yet), though that may change in the future. For my use case it wouldn't be an option to run fine-tune or heavy system prompt optimization after every run or on a weekly basis. It would get quite expensive and risky, since changing parameter weights can alter an agent’s behavior in unpredictable ways.
P.S. Open-source LLM development is vital. Without it, commercial providers could drive up token usage prices to ridiculous levels. So for now, using affordable commercial options makes sense, but open-source development should be supported heavily.
So, I decided to use the ACE (Agentic Context Engineering) approach. All my agents are self-reflecting on their own behavior and then I have another agent handling memory optimization for them. Since my agents are fully focused on providing automation, I can solely focus on procedural memory optimization. And it has been working incredible well - clearly improving over time. And I have a couple of ideas how to push things even further, but probably will write another blog post about that at some point. In short, to me it seems memory and learning are quite misunderstood concepts for agents. It’s not about pushing all the information down and then expecting it to work miraculously. It's same with humans. When you were in school, did you really understand everything after reading the textbook once? Human learning models offer some very effective methods for agents.
As a reminder, the idea of self-reflecting does not mean expecting LLM to truly being able to analyze its own behavior intelligently. LLMs are just token-prediction casino slots, not soon-to-be AGIs reasoning and analyzing their existence. But that doesn’t mean you cannot cement LLM’s "behavior", since each LLM model has different parameter weights. And then analyze which information is needed to pass as a context data to get optimized results. Instead of trying to find global minimum and treating it as an optimization problem, we are moving towards simulation world and trying to mimic experiences, creating new information. And for this approach, ACE works really nicely. Trying to understand and maintain the same “behavior” while still improving task handling by optimizing procedural memory.
To ensure quality really improves and doesn’t just drift in different directions, I have set up my own testing approach. Thanks to Databricks’ excellent metadata management, it’s possible to automate the necessary information processing, both for input and for validation.
Building self-improving multi-agents to automate Databricks - mission accomplished
So much talk, so time to show a small demo version in action. Since this is in reality an autonomously running agent, I’m not concerned with latency but with robustness and continuous learning. In this version I have included a sparring agent named House, which will handle any targeted questions from KRATTI on my behalf. KRATTI uses a dedicated service principal with carefully defined permissions, so I can give it full freedom. Thanks to Databricks’ excellent monitoring capabilities, I can see everything in the logs. I have also developed an automatic permission elevation solution to tackle temporary extra permission needs, but that’s a topic for another time. The idea is to allow the agents to experiment with new things and discover better ways of operating, but within a controlled environment. This way they develop by encountering different scenarios, instead of solely being optimized with a training dataset to find a global minimum.
Since I was able to build this with a Coca-Cola and pizza budget during the weekends, you might ask why not all companies have automated Databricks management in a similar way? Well, because I’m a busy guy.
Just joking, but each company has its unique people and business processes. For example, this setup works amazingly for me because it has been optimized for my own personal needs. Databricks is a "closed" ecosystem, nicely standardized and documented, which makes it a perfect candidate for this. But in an enterprise ecosystem, it’s a bit different when there are hundreds of users and multiple teams working with different needs. Yes, you could have a one-size-fits-all setup, but it would be mediocre at best - wouldn’t be optimized or tailored for value creation based on your unique requirements. It requires unique, custom agents to achieve a real competitive edge, not low-effort C-agents, which the market is flooded with nowadays. Using general low-code/no-code agents without proper understanding may give you a short-term boost at the cost of long-term value. Black-box solutions always come with a risk.
Agents need to be integrated as part of your business entity, otherwise, they remain fun PoC projects that just lose money. But if you manage to embed agents seamlessly, that’s the sweet spot. The transition has already begun and will reshape the future. It’s time to move beyond this ridiculous agent-hype bubble and focus on creating solutions that deliver real long-term value.

Written by Aarni Sillanpää
Don't outsource common sense to LLMs



Comments